# Scalable Software Development Automation
This article is a continuation of Defining Implementations and Automating Software Development. For context those two are recommended to be read first.
Using Definitions we can represent natural language descriptions to data structures, which are code readable. That can be used in order to validate our software implementation against the defined specifications. We can utilize this concept to define a workflow that produces our feature's scaffolding from Definitions. Code can be produced and updated dynamically giving the developer more time for implementing business logic.
Let's define a workflow that consist of:
- Definitions
- Definition records (json files from our previous article)
- ScaffoldGenerator
Following the example from our previous article we have three Definition records for one feature Model, Request, Response. This group of files describe the implementation details of one feature. We can have many groups that each one describe one feature. All the groups define our whole Domain.
There is a correlation between Definitions and Definition records. We can see that the Definitions act as our schema for the implementation and our Definition records as the implementation details for our features.
# With that said, we could say that Definitions are like a database schema and Definition records are like records in that database. But this database describes implementations not a traditional Business Domain. ScaffoldGenerator is the database engine
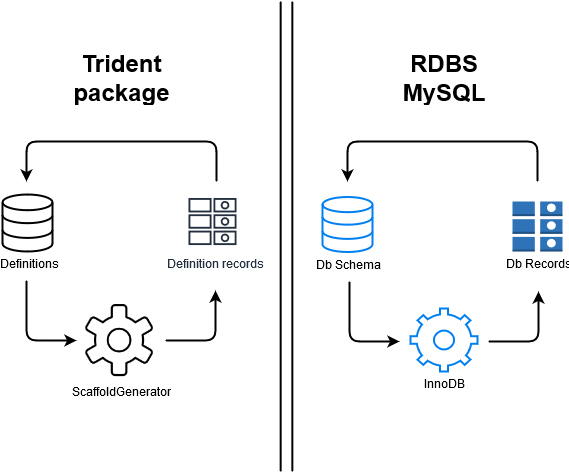
Definitions - RDBS comparison
If we think of Definitions and Definition records like that then we apply many concepts that are used in databases here.
For example:
- bundle Definitions and Definition records together (like a db dump). When executed by the engine (ScaffoldGenerator) produce the same scaffolding
- Having our engine define Read, Create, Update, Delete in the generated code we can
- make mass updates to specific Definition record values and "apply" them to the previously generated code. This is more like a database update but here we can refactor code precisely in a project wide scale
- split our code base into many smaller ones. Having precise Definitions we could define the parts of our code that contain our business logic and create new Projects with parts of it and generate scaffolding on top
- Have different engines which implement the Definitions in a different way and migrate implementations from one structure/architecture to another, similar to changing databases
- Build tools for observability, monitoring. Like in a database scenario, the whole schema can be depicted as a graph. Here this graph represents our architecture. Different records can be shown visually, and have a more intuitive way to present errors or performance hits in our application.
- Check the implementation of features. If the implementation does not much the specification (Definitions) from what has been decided the project cannot be build (in our Continuous Integration pipeline for example).
Of course there are many more cases that can be discovered seeing the Definitions - Definition records as a traditional database with it's data.
# Github
The concepts that have been described in this and the previous articles are used in Trident and Vista. The goal of the packages is to build and manage the scaffolding that is needed in order to focus only on implementing business logic for Laravel applications. Specifically the update/refactoring can be seen implemented in Trident and through Butler.
Butler is a tool that has been build with Trident and Vista in order to make the management of applications made with these packages easier. It provides a UI which reflects the CLI commands of both packages.
links:
- Butler: https://github.com/j0hnys/butler
- Trident: https://github.com/j0hnys/trident
- Vista: https://github.com/j0hnys/vista